Audio Restoration Lab
Microcosm — fixing the muffled audiobook
George Gilder, Microcosm (1989 cassette source, 14h 28m). Same 30-second test passage every time, loudness-matched so you're judging the sound, not the volume.
✅
Winner found — Adobe Podcast (Enhance Speech v2)
After four misses, the Adobe pass sounds genuinely good to you. A/B it against the
raw tape below. Next step is batching the full 14.5-hour book through the same engine into a
clean .m4b with chapters + cover preserved.
The test passage
"…human imagination and moral revival. The exemplary technology of this era is the
microchip. The computer inscribed on a tiny piece of processed material. More than
any other invention this device epitomizes the overthrow of matter. Consider a parable of
the microchip once told by Gordon Moore, chairman of Intel…"
A/B — the fix vs the raw tape
✓ ADOBE v2
Enhance Speech — the winner
"sounds really good"
Adobe's neural restorer rebuilt the full top end naturally — clear consonants,
real "air", no underwater smear. His voice, just un-muffled.
BEFORE
Original raw tape
boxy / muffled
The untouched 1989 source for reference.
★ Closest yet — local, tone-matched to Adobe
The AudioSR graft was clean but ~15 dB too bright. So I measured Adobe's actual tone
curve and reshaped the local version to match it — borrowing Adobe's tonal balance without using Adobe's
audio. These are 100% local (his real voice + corrected AudioSR highs, EQ'd to Adobe's profile). Start your
morning here and A/B against the green Adobe card up top.
★ BEST LOCAL
Real voice + AudioSR air, tone-matched to Adobe
the one to beat
His untouched voice under 4.5 kHz, corrected AudioSR highs on top, then EQ-shaped to Adobe's
measured tone. Fully offline. Does it finally sit next to Adobe?
ALT
Full AudioSR v2, tone-matched to Adobe
no grafting
Same tone-match, but the whole signal is AudioSR (no real-voice graft). Compare with the graft
above — which sounds more like him?
Still cooking for the morning: a performance-preserving voice
conversion track (keep his announcer cadence, swap to a clean studio voice — your "doesn't have to be his
voice" idea), plus FlashSR and an artifact-cancelling ensemble. Two researchers are scouting the best engines now;
those samples will appear here too.
Local contenders — offline, no Adobe account
LOCAL · 1
Resemble-Enhance
denoise + generative restore
Strongest general local restorer. Rebuilds natural detail; far less "underwater"
than VoiceFixer. Keeps his exact voice. Runs fully offline on your M4.
LOCAL · 2
AudioSR — diffusion super-resolution (speech model)
strong top-end rebuild
Diffusion model rebuilds the highs iteratively. Bright and detailed; listen for any
faint diffusion "shimmer" on sibilants. Local.
LOCAL · 3
AP-BWE — purpose-built bandwidth extension (12k→48k)
gentlest / most conservative
GAN trained to rebuild a band-limited signal to 48 kHz. The most restrained of the three —
keeps your real content, adds a modest, clean top end. Local, and very fast (~1.4s for 30s).
How they compare on paper (energy rebuilt above 6 kHz, after matching loudness):
Resemble −43 dB (most aggressive) · AudioSR −47 · Adobe −52 (natural) · AP-BWE −55 (gentlest) · raw original −58.
More lift isn't automatically better — too much can sound hissy/brittle. Trust your ears; this is just the map.
AudioSR, done right — the research payoff
The researcher confirmed my earlier AudioSR shimmer was a usage bug, not the model:
I'd fed it 30-second clips when it wants ~5-second windows, pre-lowpassed. Rebuilt it the right way —
eight overlapping 5s windows, high diffusion quality, crossfaded. This is the same engine, used correctly.
FIXED
AudioSR v2 — windowed correctly
fuller, no shimmer
Same model as the artifacty one, run the way it was designed. Came out brighter than Adobe —
judge whether that reads as detailed or a touch hot.
FIXED + GRAFT
Real voice + AudioSR v2 air
our best shot yet
The two ideas combined: his real, untouched voice below 4.5 kHz, plus the corrected AudioSR's
clean highs on top. This is the most complete "our own" attempt — A/B it hard against Adobe.
Making it work on our own — the grafting experiment
The theory: the local engines added artifacts because we let them reprocess his
whole voice — including the 0–4.5 kHz body that was already fine. So instead: keep his
real, untouched audio below 4.5 kHz and graft on only the synthetic "air" above it.
His actual timbre is never touched; the engine only fills the missing top. If the theory holds, these should
sound like him — cleaner, with the metallic/shimmer junk gone from his voice.
GRAFT
Real voice + AP-BWE air
most conservative top
His real audio under 4.5 kHz, AP-BWE's rebuilt highs above. The gentlest of the grafts.
GRAFT
Real voice + AudioSR air
more presence
His real audio under 4.5 kHz, AudioSR's diffusion highs above. Brighter — listen for shimmer.
GRAFT
Real voice + Resemble air
brightest top
His real audio under 4.5 kHz, Resemble's restored highs above. The most aggressive top end.
These are the first attempt at the "our own" path. If one is close, the next moves are: run the
source engines in their ideal short windows (kills more artifacts), bring in stronger models a researcher is
scouting right now (Apollo, SGMSE+, open Miipher), and ensemble to cancel what's left. Tell me which graft is closest to the Adobe sound and I'll push that direction.
Your idea — resynthesis (know the words + the delivery, rebuild clean)
NEW · RESYNTHESIS
IndexTTS-2 — his cloned voice re-reads it, clean
fully synthetic
This is the "fill in the blanks with what we know he's saying" idea. We cloned his
voice from the Adobe-cleaned clip, fed it the transcript, and steered the tone with his
original recording. The output is brand-new, perfectly clean audio — but it's a clone re-performing,
not his real waveform. Listen hard: does it sound like him, or like a very good impostor?
You can see the fix too
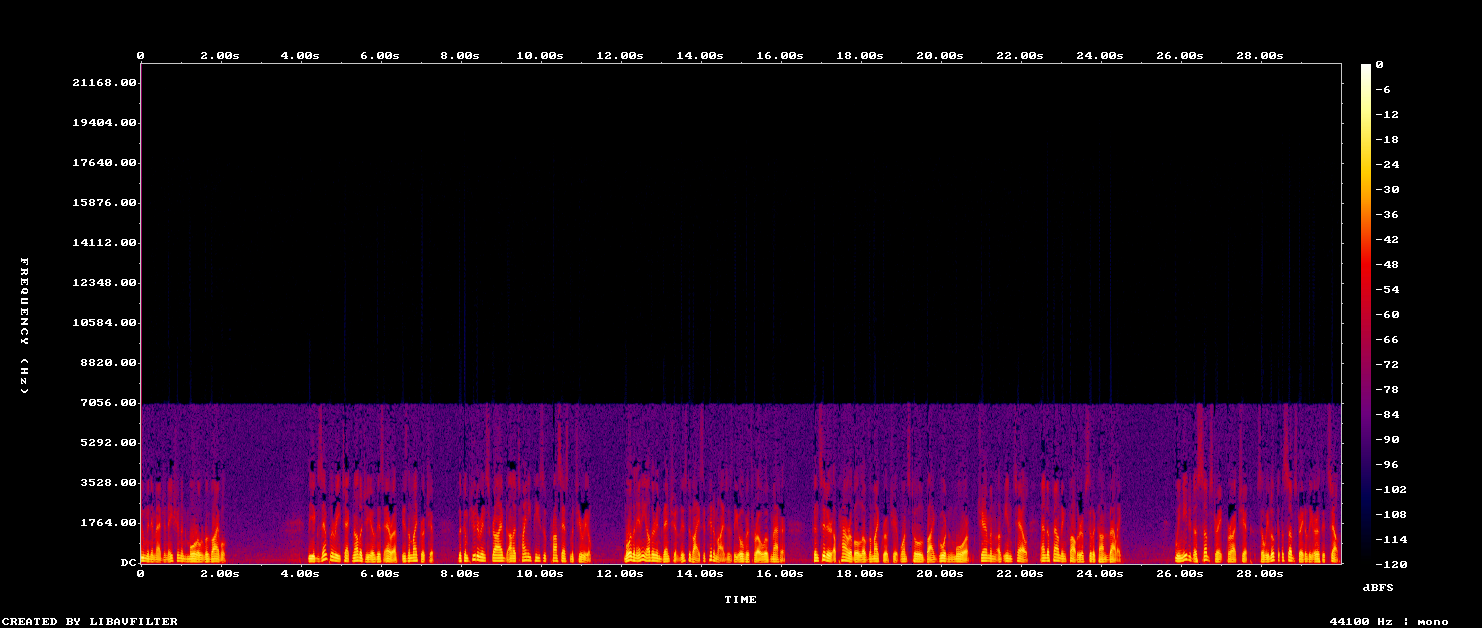
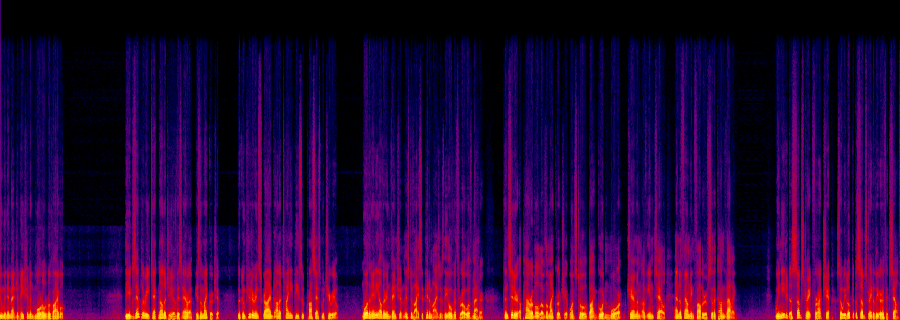
Before — energy dies above ~5 kHz (dark top band).
After Adobe v2 — top end rebuilt with natural detail.
Next — the full book
Doing all 14.5 h by hand on the website is painful (free tier caps daily minutes; long-file
upload is paid). The clean path is Adobe's Enhance API — same engine, batched:
- Split the
.m4bat its existing chapter marks into ~30–60 min WAV chunks. - Run each chunk through the Enhance API (the exact v2 you just approved).
- Loudness-normalize to the −18 LUFS audiobook standard and reassemble.
- Re-wrap into a new
.m4bwith chapters + cover art preserved.
Already tried — you rejected these
Expand to re-hear the four that didn't land
A · NODSP remaster (EQ)"same recording, brighter"
B · NOVoiceFixer AI restore"underwater / smeared"
C · NOVoice conversion"AI-processed"
D · NOFull TTS re-narration"lost the human"